


Your Data Should Be Plaintext Files
AI will automate a github repo with markdown far more easily than a notion database.

Artificial Intelligence works best on text. Long strings of text. That means AI works especially well inside of text editors. The most famous interactive text editor where humans work collaboratively with AI right now is a text editor called Cursor.
Now, Cursor might brand itself as a code editor, because that is its primary purpose and its target audience, but it works equally well for any structured text. Let’s look at some examples.
Cursor is a great markdown editor, which makes it a great PDF editor. Why wrestle with Microsoft Word when an AI can format your Markdown document in seconds.

Cursor is a great editor for building flowcharts and graphs. Why manually build a flowchart in powerpoint when an AI model can write a mermaid diagram in 0.2 seconds.

Cursor is a great editor for your Knowledge Graph (or Personal Knowledge Management system, or Zettelkasten, etc…). Why give Notion all your data when you can just use AI on plaintext?
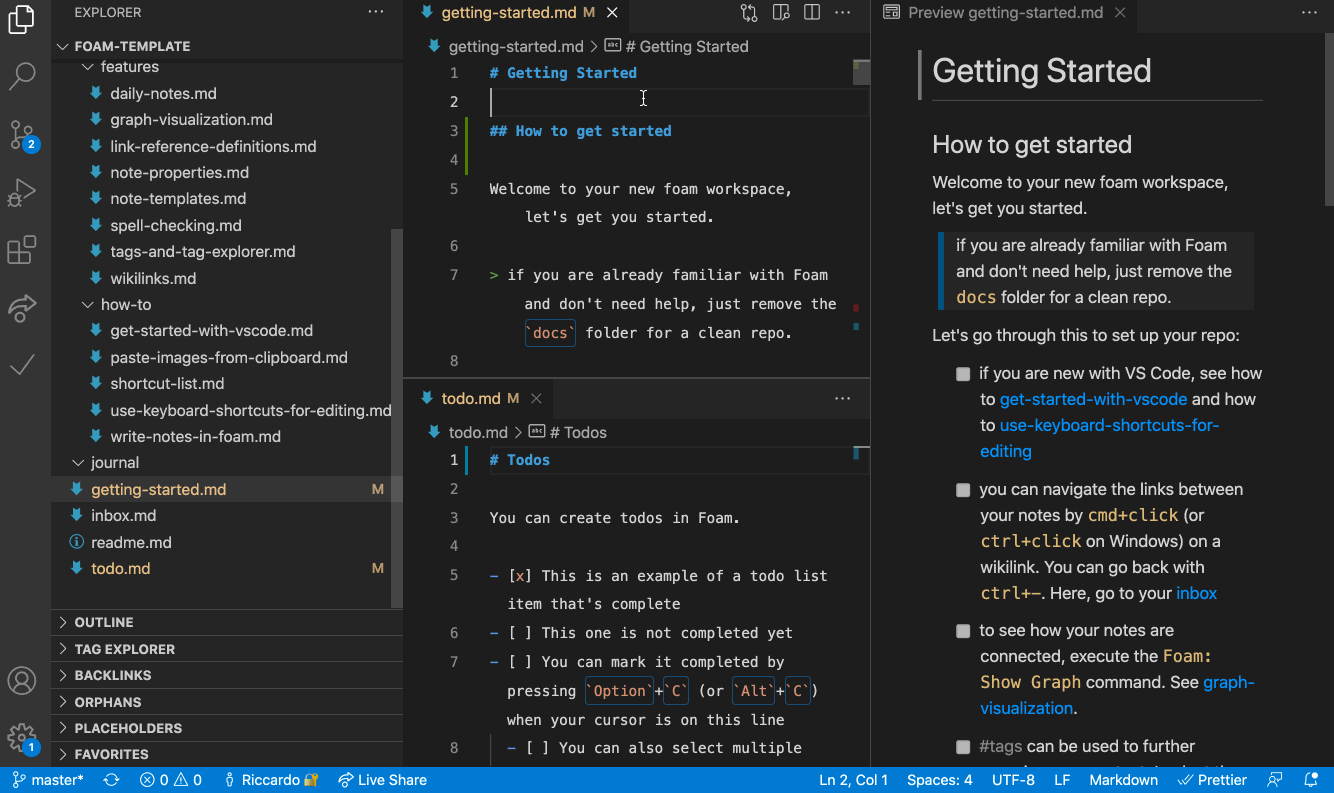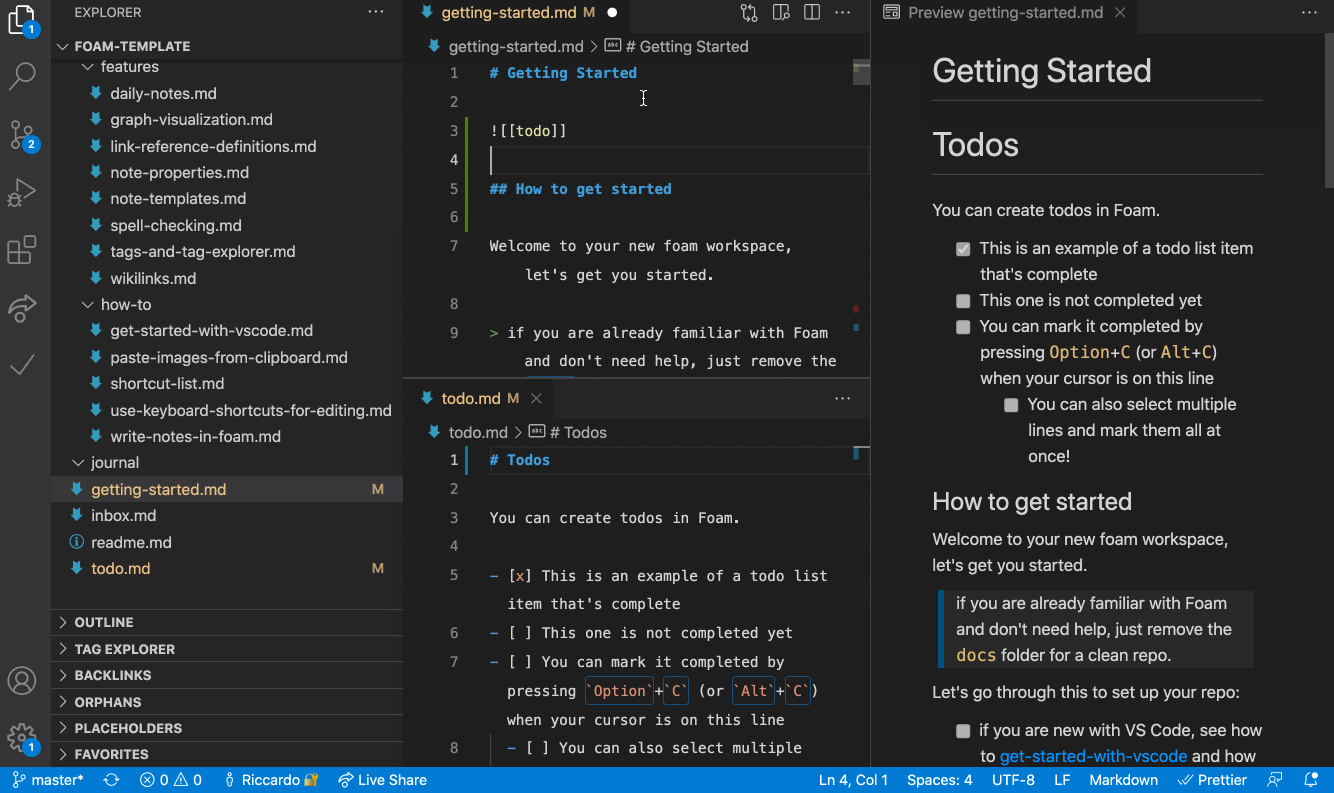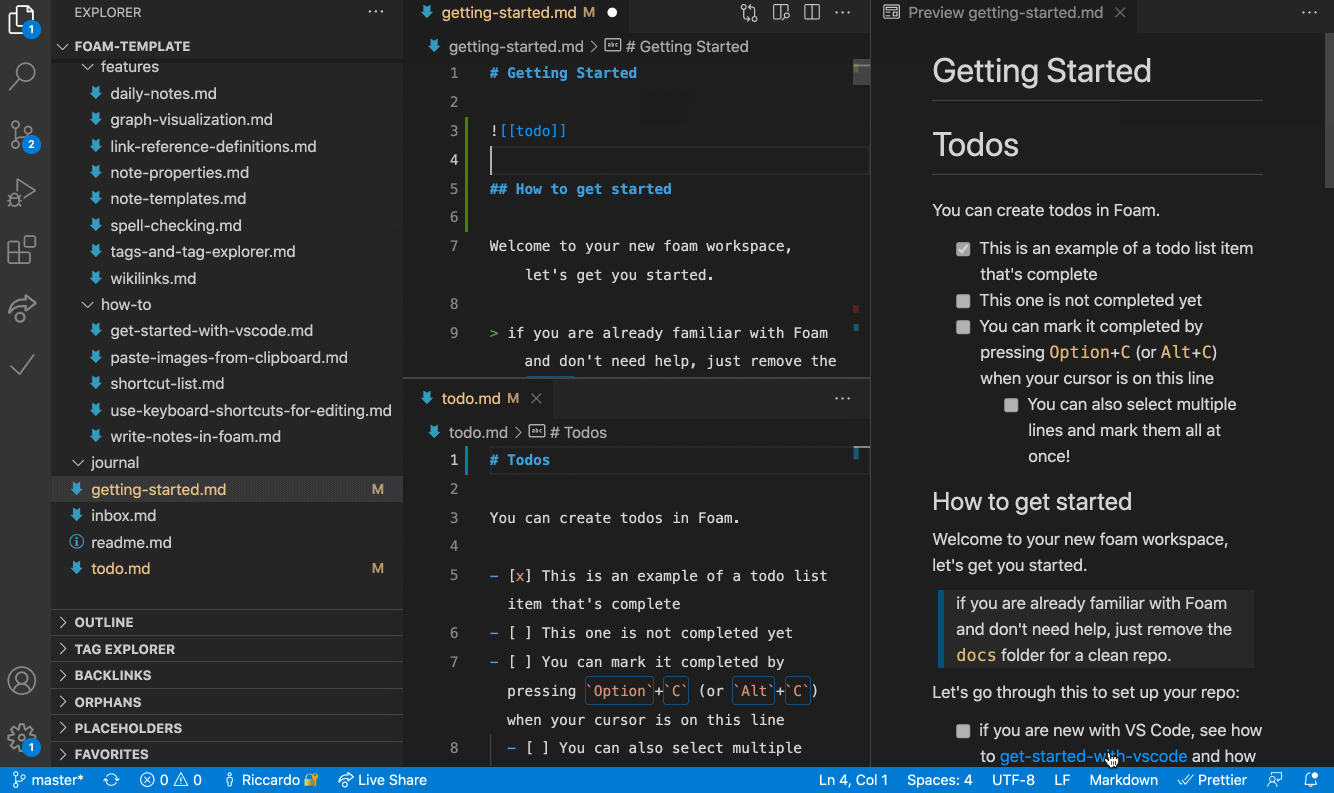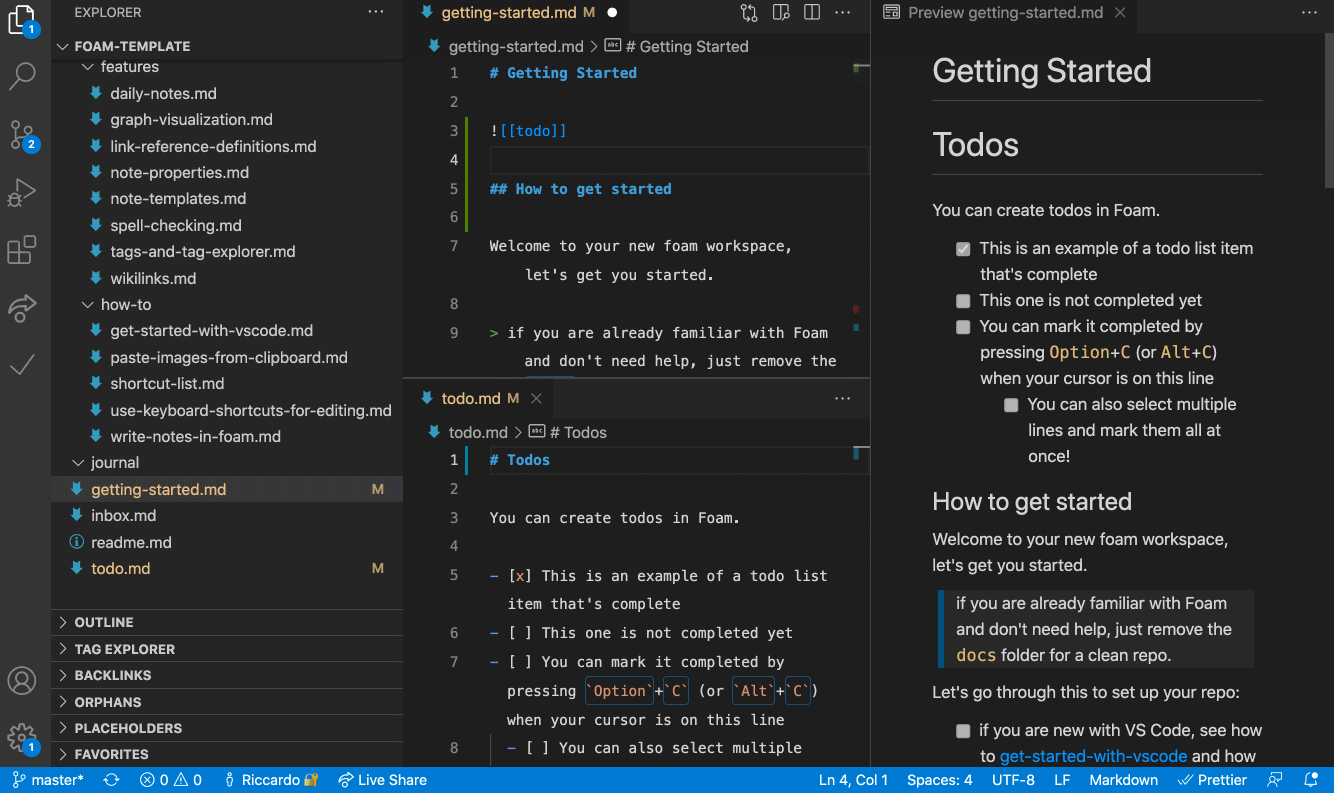
Cursor is a great editor for drawings and vector images. (Okay, this is an exaggeration, but I do think open source vector drawing apps like TLDraw integrated into cursor which automatically convert to svg are an interesting idea, and you CAN edit the SVG directly yourself or with the help of an AI):

There are other advantages to storing all your data in plaintext files. Let’s discuss:
Version Control Sch-mersion Control
If you use plaintext, you can upload all of your files to Github, which will basically host them for free, forever, with complete version history of every change you’ve ever made, and the ability to collaborate with anyone in the world, on any device in the world, because every single device knows how to read and edit plaintext files.1
I’ve previously argued that the law should be stored as plaintext files on Github, rather than however it is stored now (often Microsoft Word documents converted to PDFs, and sometimes books, which is obviously not ideal).
Own Your Data
Want to know the worst thing about having all your data trapped in useless data structures hidden behind another company’s API? You don’t fucking own it. Just try to zip a piece of it up and email it.
I’m going to quote from the todo.txt manifesto writers, who have been advocating for plaintext data far longer than AI has been around to make their point obvious:
Why plain text?
Plain text is software and operating system agnostic. It's searchable, portable, lightweight, and easily manipulated. It's unstructured. It works when someone else's web server is down or your Outlook .PST file is corrupt. There's no exporting and importing, no databases or tags or flags or stars or prioritizing or insert company name here-induced rules on what you can and can't do with it.2
All Data Is Text Anyway
At the end of the day, all data has to be serializable to text anyway, because that’s how computers communicate with one another! In plaintext! (well, it’s complicated, but basically). You can get some benefits at scale for storing your data in specific, easily indexed ways when you have A LOT of data, but you can also just create indexes which are separate from the plaintext data, which is what search engines do, and what Github does.
Because AI that understands text is already here, and It Keeps. Getting. Better.
Look, if you don’t want to take advantage of version-controlled, collaborative, AI-editable, easily shareable, stupid-simple plaintext data formats for all of your applications, you do not have to.
But the fact of the matter is, plaintext files will keep getting better, and working with them is already far more enjoyable than working with most corporate bloatware.
Why would I ever use Microsoft Word when I can edit my own markdown files with Claude built into my text editor, I can do it collaboratively using Github or VSCode liveshare and then use pandoc to convert them to ANY OTHER markup language (including PDF, HTML, or Microsoft Word format itself)?
I simply would not. This will become increasingly true for every other type of simple data application, especially any which are in the traditional “office” suite of tools.
yes i know this is a run-on sentence i did it for effect
https://github.com/todotxt/todo.txt
such a keen way of levelling up your knowledge base - i keep notes in obsidian which is automatically in markdown, and now i wanna try opening it thru cursor and play around w what i can do!
What kinds of notes/non-code content would you want an LLM to help you with?
I use Cursor for my personal website and it has a very annoying habit of injecting or even substituting slop copy over my own copy, it keeps trying to "help" me with my plaintext and I wish it would stop!
Can only imagine it would be even worse with a simple markdown file like I use in Obsisian